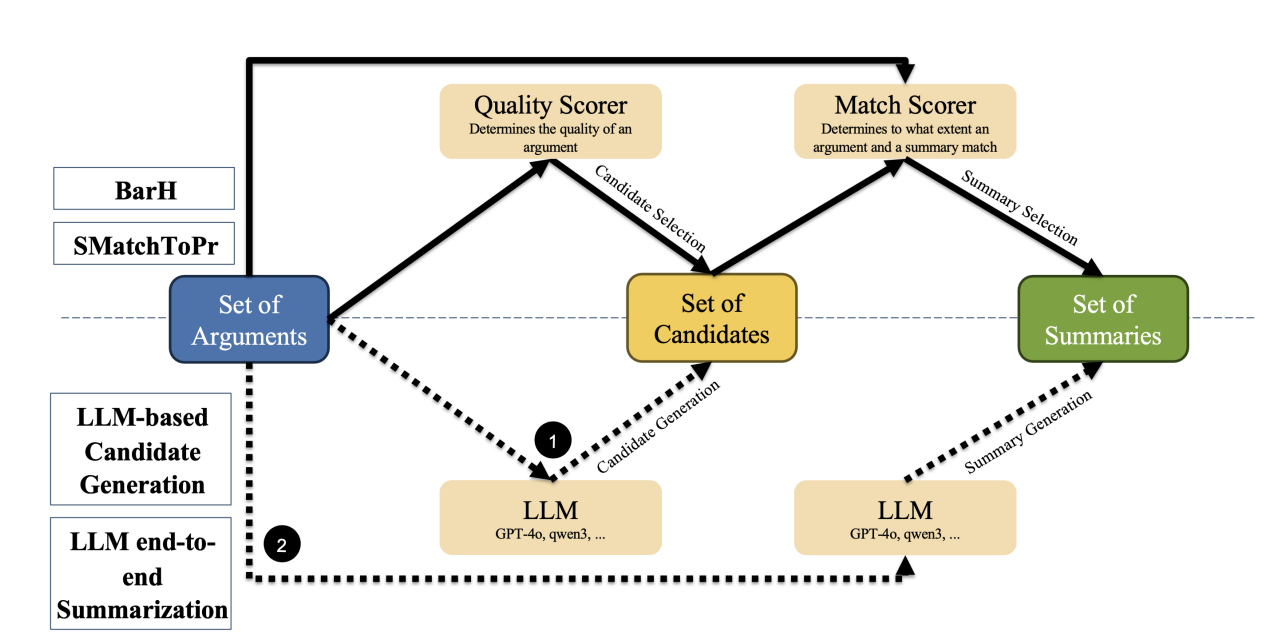
In this post, our CTO Benjamin Schiller discusses some surprising findings from our latest experiments on argument mining and semantic search. This post adds to our series on LLMs and RAG (after Part 2 and Part 1).
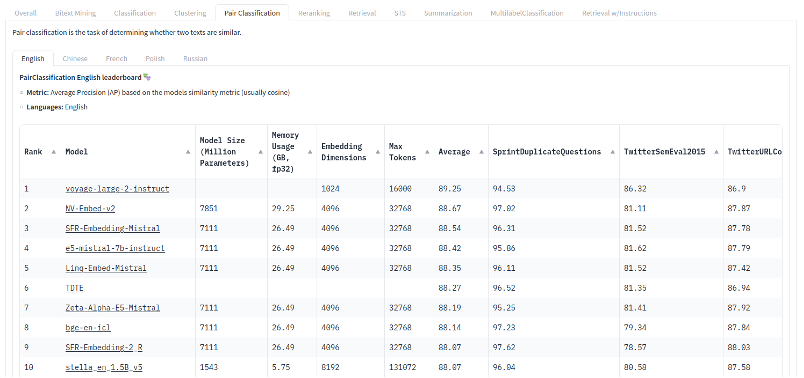
We lately ran a bunch of experiments inspired by some advances on the MTEB Leaderboard. I am finding the results puzzling. None of the newer, state-of-the-art, models performed well on the domain-specific tasks on which we tested them (mostly, argument mining). Instead, some of the good old 2020ish models are still very competitive – if not better.
The Influence of Cross-Domain Settings
While this sounds pretty counter-intuitive, it matches our experiences from other LLM projects. To give some background on the experimental setup, it is important to mention that our evaluations are strictly cross-domain. This means we always train and test on different sources and topics. For example, when a model is trained to identify political arguments on social media, we also test this model on product reviews. Models that overfit (i.e. focus too much) on either topics (e.g. around technical innovation like “artificial intelligence” etc.) or certain types of data (e.g. short postings on X/Twitter) are punished more than those that trade precision on a single topic/domain against broader, cross-domain knowledge. Even larger models (more parameters, more training data) are not necessarily better for a domain-specific task. In our experience, advances on leaderboards often do not tell too much for our internal use cases. This as they tend to overfit on the domains and tasks of the respective leaderboards (MTEB, in our case).
Semantic Search and Embeddings
We see a similar effect in semantic search. Semantic search heavily depends on embeddings, and embeddings by nature are very domain dependent. Newer embedding models, which include more context, seem to be even more prone to this problem. Furthermore, embedding longer contexts comes at the cost of speed and resources. Compression solves this problem to a certain degree, but will lose detail at the expense of the precision required for searches on very specific topics.[1] In the end, standard BM25 is still a very strong baseline for many applications (also see Part 2 of this series).
It seems, despite all the impressive advances in LLMs, for most real-world applications, that there are quite some challenges to solve in argument mining and semantic search. If you’re interested in how SUMMETIX tackle the challenges of customer intelligence and support with argument mining and LLMs, reach out by sending a LinkedIn message or completing the form on our website.
[1] If you want to dive deeper on this topic, we highly recommend this episode of the “How AI is Built” podcast with our former UKP Lab colleague Nils Reimers.